|
This is Chiyu (Henry) Ma, a third-year Computer Science Ph.D. student at Dartmouth College 🌲, where I am fortunate to be advised by 🌟 Prof. Soroush Vosoughi. Currently, I am also a Research Intern at Qwen Pilot, focusing on research in large-scale post-training of Large Language Models (LLMs). Previously, I earned my M.S. in Statistical Science from Duke University 💙. As a member of the Interpretable Machine Learning Lab, I worked under the guidance of 🌟 Prof. Cynthia Rudin and collaborated with 🌟 Prof. Chaofan Chen (UMaine). I hold a B.S. in Statistics with Honors (Computational Finance concentration) from Carnegie Mellon University 🤖, where I conducted research on statistical analysis in biological applications advised by 🌟 Prof. Zach Branson. / / / Google Scholar |

|
|
My prior research centered on Interpretability in Computer Vision Models (CNNs and ViTs) and ensuring the reliability of LLM-as-a-Judge frameworks. Building on this foundation, I have pivoted to Large-scale Post-training, where I design algorithms specifically aimed at eliciting and enhancing the complex reasoning capabilities of LLMs. |
|
[May, 2026] Three papers accepted to ICML 2026, and two papers accepted to ACL 2026. Thanks to my excellent collaborators!
[March 20, 2026] We release our first Technical Report for Qwen Pilot Team! Thanks to my excellent collaborators!
[Jan. 28, 2026] Two papers accepted to ICLR 2026. Thanks to my excellent collaborators. See you in Rio!
|
|
Some interesting papers about my work and research on LLM Post-training and Reinforcement Learning. |
|
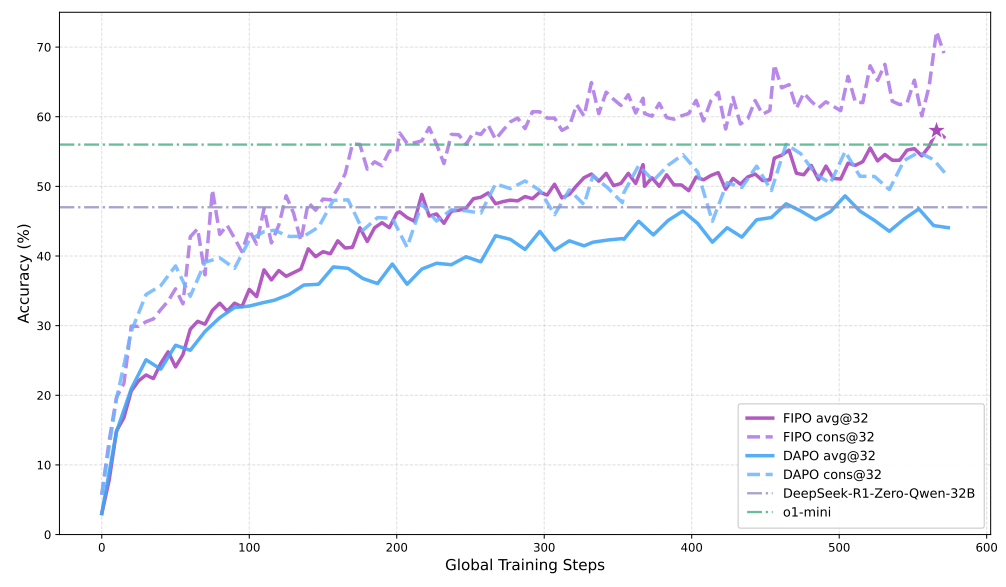
Chiyu Ma*, Shuo Yang*, Kexin Huang, Jinda Lu, Haoming Meng, Shangshang Wang, Bolin Ding, Soroush Vosoughi, Guoyin Wang, Jingren Zhou Tech. Report Paper This paper proposes that FutureKL Influenced Optimization that sucessfully break the performance ceiling observed from GRPO based training recipe by providing dense advantage signal. |
|
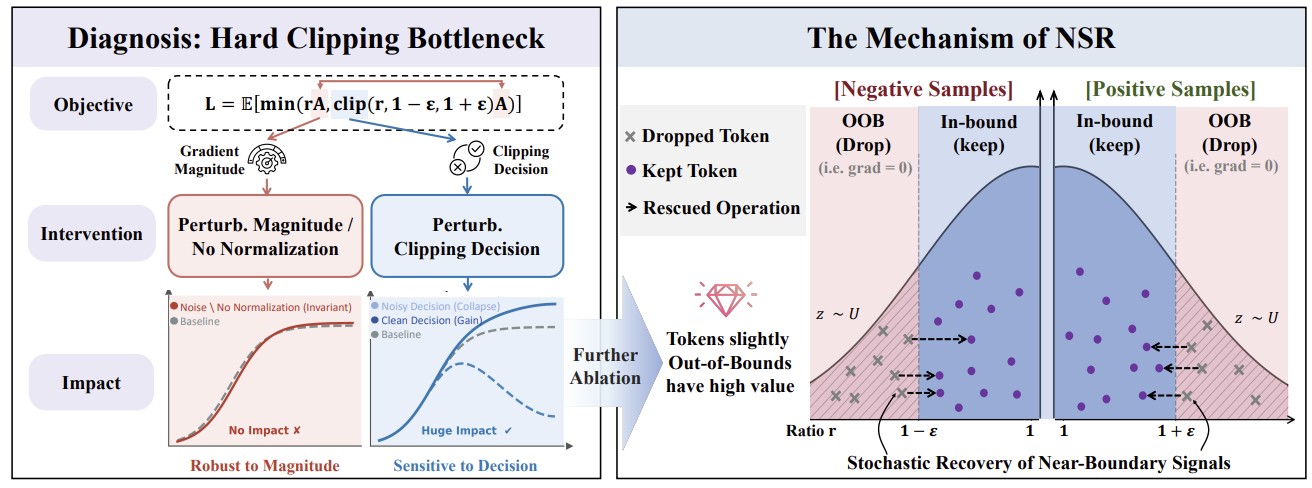
Shuo Yang, Jinda Lu, Chiyu Ma, Kexin Huang, Haoming Meng, Qihui Zhang, Yuyang Liu, Bolin Ding, Guoyin Wang, Li Yuan, Jingren Zhou ICML 2026 Paper This paper proposes Near-boundary Stochastic Rescue (NSR), a minimal, plug-and-play modification that stochastically retains these slightly out-of-bound tokens to recover lost signals. |
|
Shuo Yang, Jinda Lu, Kexin Huang, Chiyu Ma, Shaohang Wei, Yuyang Liu, Guoyin Wang, Jingren Zhou, Li Yuan ICML 2026 Paper This paper proposes One-Way Policy Optimization (OWPO), a method based on the principle of decoupling optimization direction from update magnitude. |
|
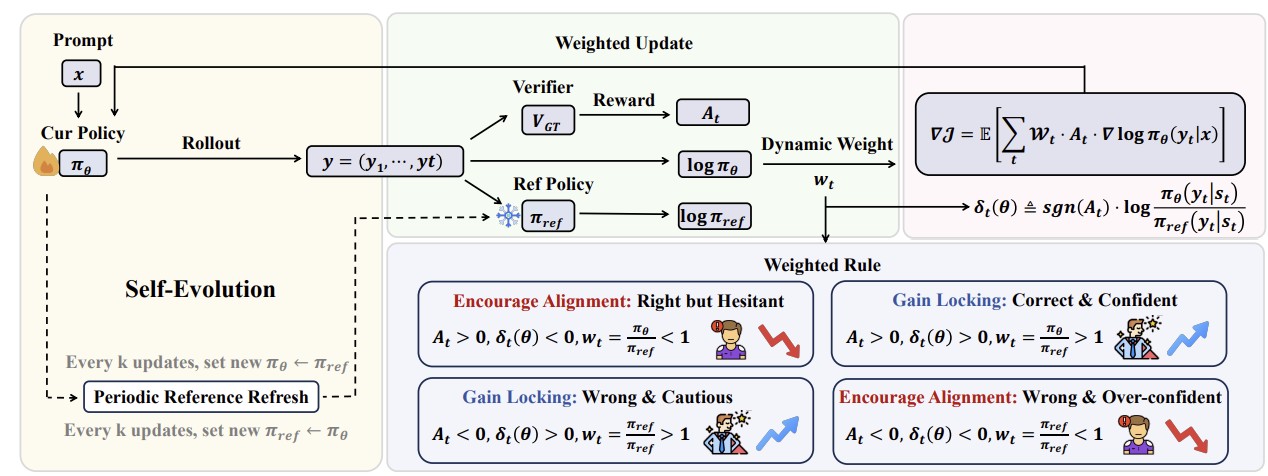
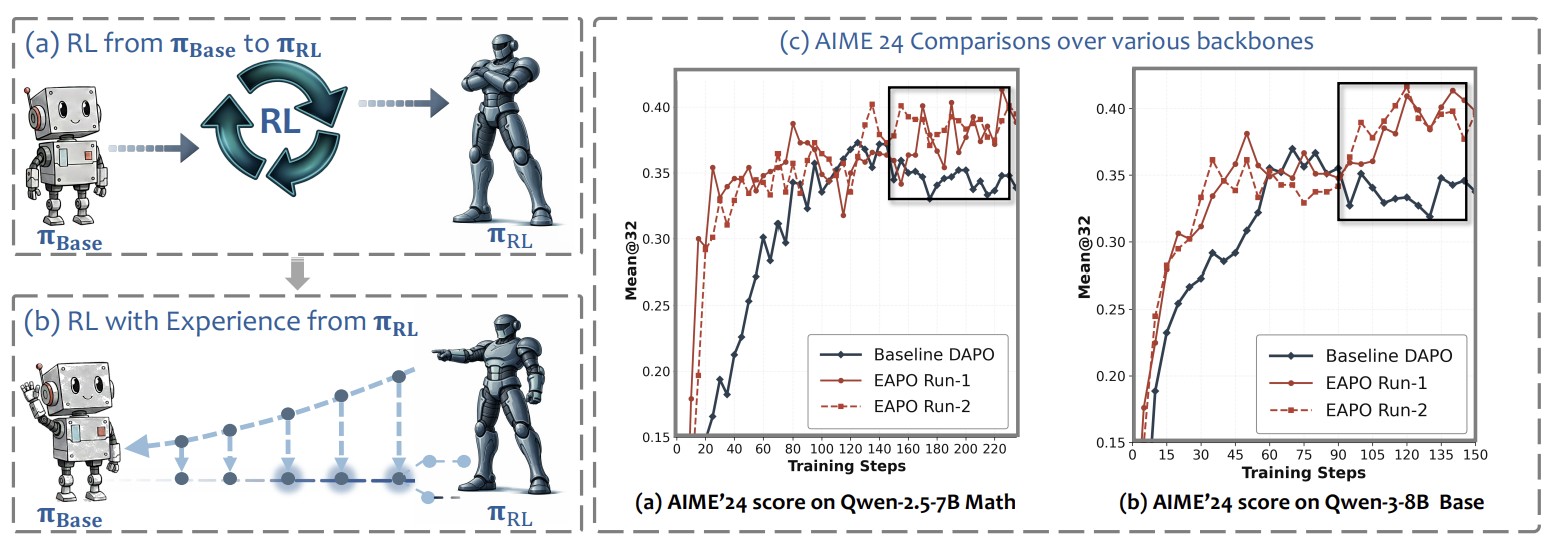
Jinda Lu, Kexin Huang, Junkang Wu, Shuo Yang, Jinghan Li, Chiyu Ma, Shaohang Wei, Xiang Wang, Guoyin Wang, Jingren Zhou ICML 2026 Paper This paper proposes Experience-Augmented Policy Optimization (EAPO), which leverages a prior RL-optimized policy as an action-level experience prior and selectively injects experience at critical decision points during rollout. |
|
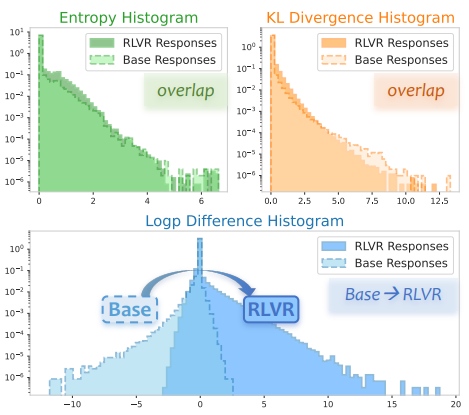
Kexin Huang, Haoming Meng, Junkang Wu, Jinda Lu, Chiyu Ma, Ziqian Chen, Xue Wang, Bolin Ding, Jiancan Wu, Xiang Wang, Xiangnan He, Guoyin Wang, Jingren Zhou ICLR 2026 Paper This paper proposes that log-probability difference is a more promising metric than entropy for evaluating how LLMs evolve during training, a claim supported by both empirical and theoretical analysis. |

|
Haoming Meng, Kexin Huang, Shaohang Wei, Chiyu Ma, Shuo Yang, Xue Wang, Guoyin Wang, Bolin Ding, Jingren Zhou ICLR 2026 Paper This paper sheds light on the distributional changes induced by RLVR and provides a granular, token-level lens for understanding and improving RL fine-tuning in LLMs. |
|
My earlier works on the robustness of LLMs and LLM-as-Judge. |
|
|
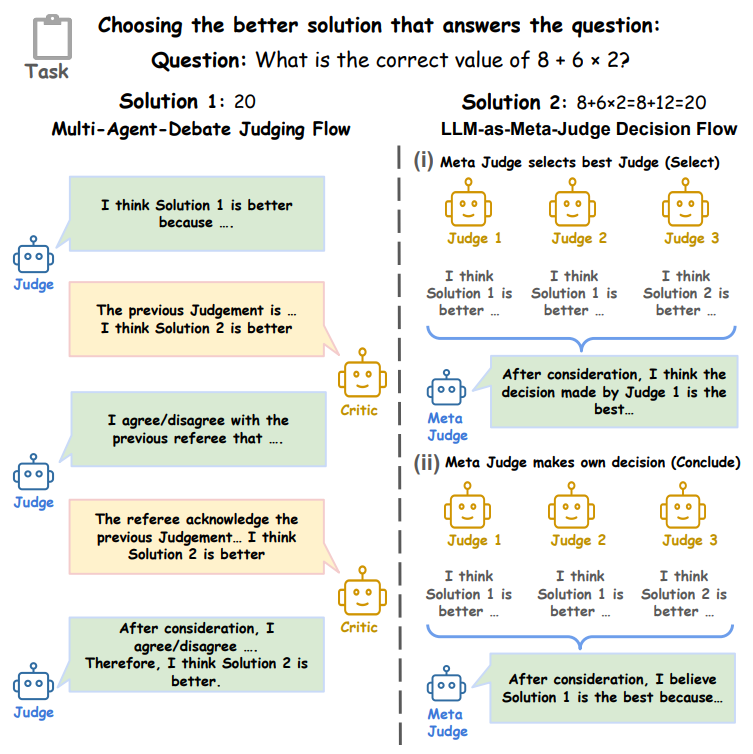
Chiyu Ma* , Enpei Zhang*, Yilun Zhao, Wenjun Liu, Yaning Jia, Peijun Qing, Lin Shi, Arman Cohan, Yujun Yan, Soroush Vosoughi Findings of EMNLP 2025 Paper This paper provides counter-intuitive findings that multi-agent based LLM-as-Judges do not always provide reliable answers as people previously thought. We explored the phenomenon of bias amplifications in both Multi-agent Debate and LLm-as-Meta-Judge settings. |
|
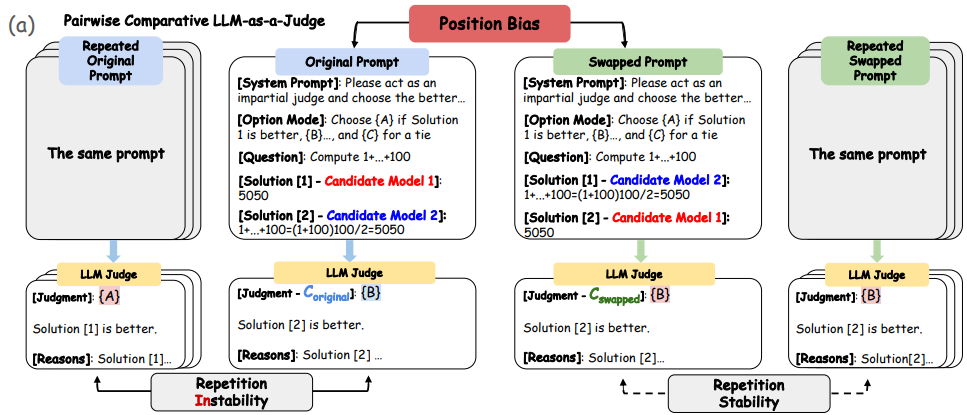
Lin Shi, Chiyu Ma , Wenhua Liang, Xingjian Diao, Weicheng Ma, Soroush Vosoughi Orals of AACL 2025 Paper This paper provides a thorough analysis on how position bias spread over pair-wise and list-wise comparisons in the state-of-the-arts LLMs such as Gemini, GPT, and Claude. |
|
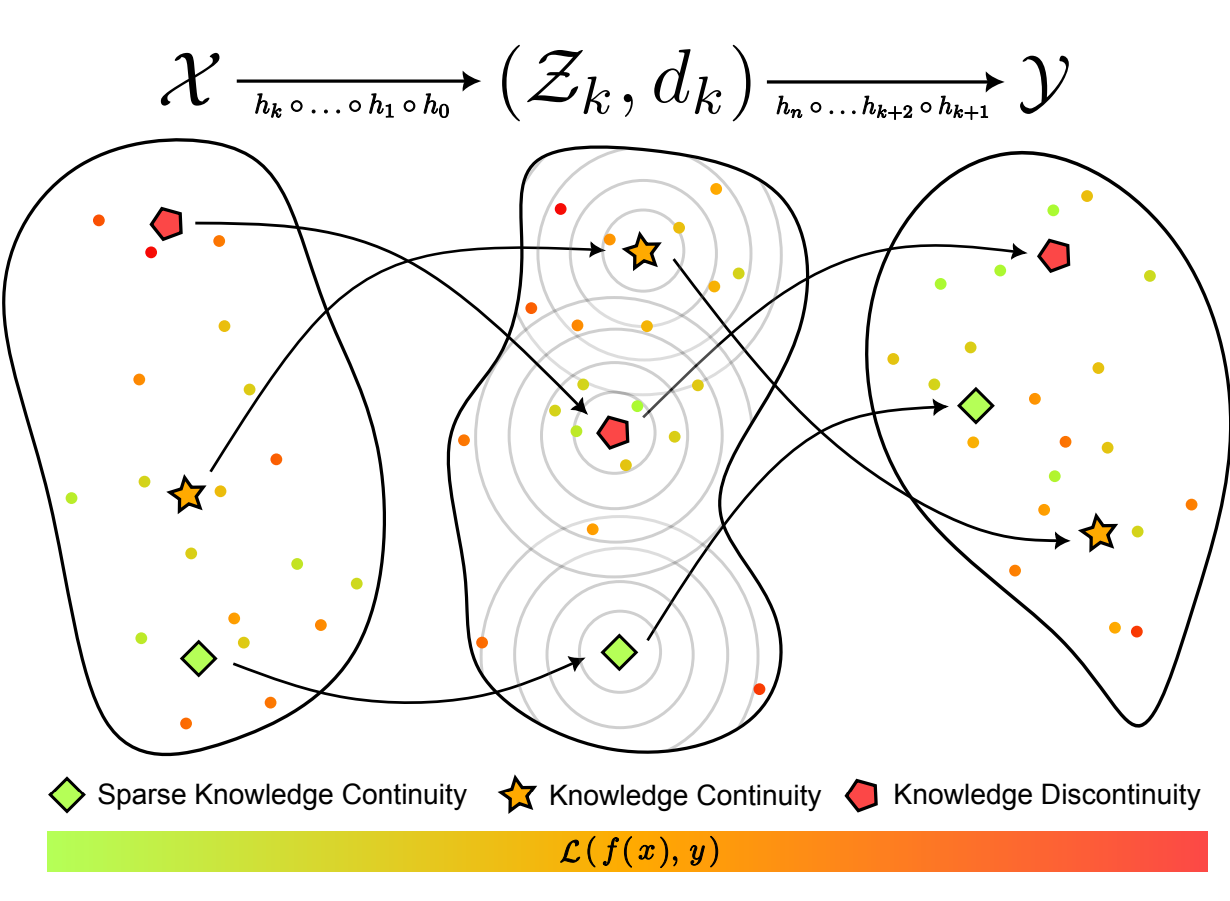
Alan Sun, Chiyu Ma , Kenneth Ge, Soroush Vosoughi NeurIPS 2024 Paper This paper proposes knowledge continuity, a novel definition inspired by Lipschitz continuity which aims to certify the robustness of neural networks across input domains (such as continuous and discrete domains in vision and language, respectively). |
My earlier works on Interpretability. Although I no longer work in this area, these projects represent a cherished part of my research journey. |
|
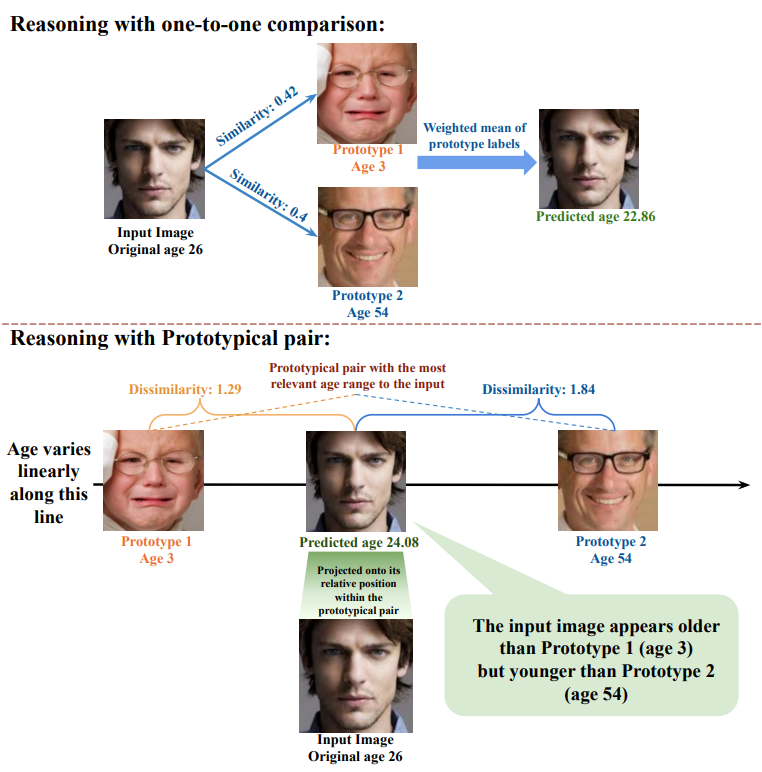
Rose Gurung, Ronilo Ragodos, Chiyu Ma , Tong Wang, Chaofan Chen NeurIPs 2025 Paper This paper propopses an interpretable alorightms with prototypical pairs for tasks with continuous labels. This algorithm is further evaluated in Reward Prediction (RL settings) and Age predictions (Classical Regression tasks). |
|
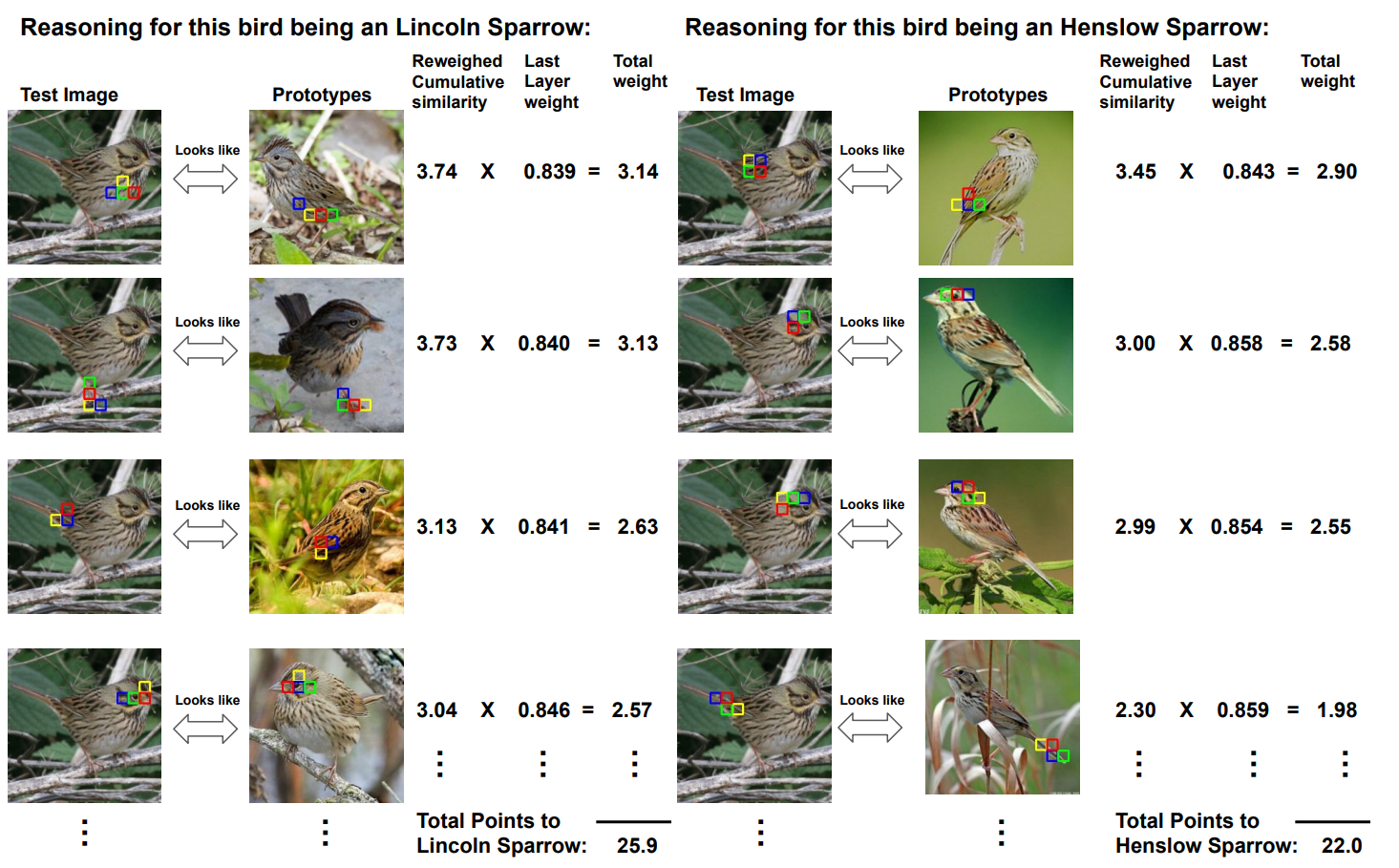
Chiyu Ma , Jon Donnelly, Wenjun Liu, Soroush Vosoughi, Cynthia Rudin, Chaofan Chen NeurIPs 2024 Paper This paper propopses an interpretable alorightms on ViTs with Prototical Parts. By greedying matching algorithms, we decomposes the prototypical parts into small patches that can freely learn features to represent a more local feature. |

|
Chiyu Ma* , Brandon Zhao *, Chaofan Chen, Cynthia Rudin NeurIPs 2023 Paper This paper propopses an interpretable alorightms on CNNs that provides geometrically equivalent visualizations of prototypical concepts. This is the first work in prototyped based methods that extract concepts from training set. |
|
Conference Reviewer: |
|
|
Design and source code from this cool guy.
|